

An earlier blog post by Jennifer Edmond on „Voluptuousness: The Fourth „V“ of Big Data?” focused on cultural data steeped in meaning; proverbs, haikus or poetic language are amongst the best examples for this kind of data.
But computers are not (yet) good in understanding human languages. Nor is statistics – it simply conceives of words as nominal variables. Quite in contrast to an understanding of cultural data as described by Jennifer Edmond, applied statistics regards nominal variables as the ones with the LEAST density in information. This becomes obvious when these data are classified amongst other variables in scales of measurement. The scale (or level) of measurement refers to assigning numbers to a characteristic according to a defined rule. The particular scale of measurement a researcher uses will determine what type of statistical procedures (or algorithms) are appropriate. It is important to understand the nominal, ordinal, interval, and ratio scales; for a short introduction into the terminology, follow this link. Seen in this context, nominal variables belong to qualitative data and are classified into distinctively different categories; in comparison to ordinal variables, these categories cannot be quantified or even ranked. The functions of the different scales are shown in the following graph:
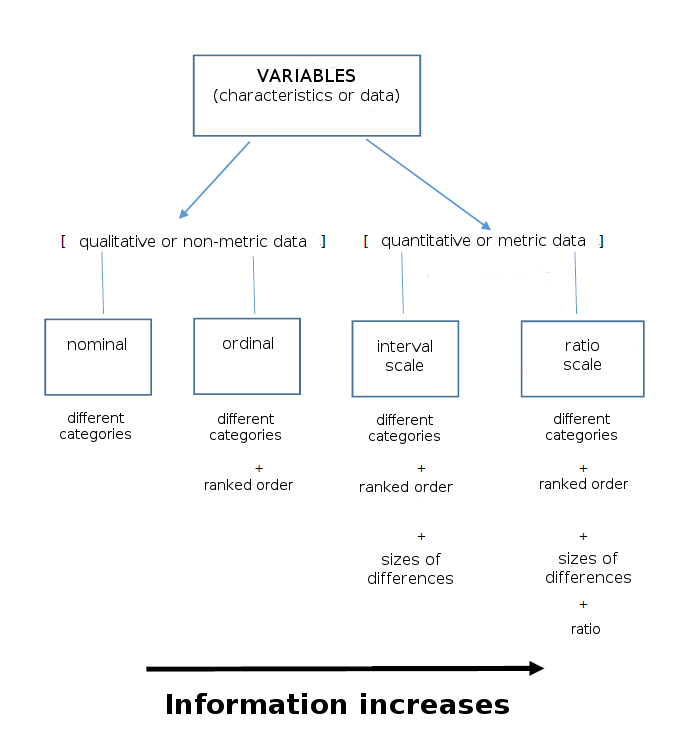
Here it becomes visible that words are classified as nominal variables; they belong to some distinctively different categories, but those categories cannot be quantified or even be ranked; there is no meaningful order in choice.
This has the consequence that in order to be able to compute with words, numeric values are being attributed to them. E.g. in Sentiment Analysis, the word “good” can receive the value +1, while the word “bad” will receive a -1. Now they have become computable; words are thus transformed into values, and it is exactly this process which reduces their “voluptuousness” and robs them of their polysemy; just binary values remain.
To my knowledge, the most significant endeavor to provide for a more complex measurement of linguistic data has been undertaken in the field of psychology: In their book “The Measurement of Meaning”, Charles E. Osgood, George J. Suci, and Percy H. Tannenbaum developed the “semantic differential” as a scale used for measuring the meaning of things and concepts in a multitude of dimensions (see for a contemporary approach f.ex. http://www.semanticdifferential.com/). But imagine each word of a single language measured – with all its connotations and denotations, each in its different functions, in the context of the other words around it … not to speak of figurative language such as metaphors, irony, and sarcasm.
This is why words – and cultural, voluptuous data in a broader sense – are so difficult to compute; and why they are the next big computational challenge.
