

An awful lot of data exist in tables, the columns (variables) and rows (observations) filled with numerical values. Numerical values are always binary: Either they have a certain value or not (in the latter case they are NAs or NULLs). Computability is based on information stored in a binary fashion coded as either 0 or 1. Statistics is based on this binary logic, even where nominal data are in use. Nominal variables such as gender, race, color, and profession can be measured only in terms of whether the individual items belong to some distinctively different categories. More precisely: They belong to these categories or not.
A large amount of data, especially in the Internet, consists of unstructured text data (eMails, WhatsApp Messages, WordPress posts, tweets, etc.). Can texts – or other cultural data like images, works of art, or music – be adapted to a binary logic? Principally yes, as the examples of nominal variables show; either a word (or an image …) belongs to a certain category or not. Quite a good of part of Western thinking follows a binary logic; classical structuralism, for example, is fond of structuring oppositions: good – bad, pure – dirty, raw – cooked, orthodox – heretic, avantgarde – arrièregarde, up-to-date – old-fashioned etc. The point here is that one has to be careful to which domain these binary oppositions belong to: Good – bad is not the same as good – evil.
But the habit of thinking in binary terms narrows the perspective; the use of data according to a binary logic means a reduction. This is particularly evident with respect to texts: The meaning of individual words changes with their context. Another example: A smile can be the expression of sympathy and of uncertainty in the Western world, while in other cultures it may be referring to aggression, confusion, sadness or a social distancing from the other. What can be seen as a ‘smile’ in monkeys is most often the expression of fear – a showing of the canines.
Indian logic provides for an example of how to go beyond a binary logic: They have something which is being called “Tetralemma”. While binary systems are based on calculations of 0 and 1 and therefore formulate a dilemma, the tetralemma provides for four possible answers to any logical proposition: Beyond the logics of 0, 1, there is both 0 and 1, and neither 0 nor 1. One can even conceive of a fifth answer: none of these all. Put as a graph and expressed mathematically, the tetralemma would look like this:
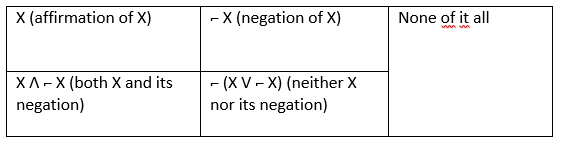
The word “dawn” would be an example for what is at stake in the tetralemma: Depending on how you define its meaning, it can be a category of its own, not fitting into a category (because of it ambivalent character), it is both day and night, and it is neither sunshine nor darkness.
One of the few philosophers to point to the narrowing of logics to binary oppositions (TRUE / FALSE) and to underline the many possibilities in language games was Jean-Francois Lyotard, in his main work “Le Différend” (Paris: Minuit 1983). In information science, it was only more recently that complex approaches have been developed beyond binary systems, which allow for an adequate coding of culture, emotions or human communications. The best examples are ontologies; they can t be understood as networks of entities, while the relations between these entities can be defined in multiple ways. A person can be at the same time a colleague in a team, a partner in a company, a father of another person working in the same company (a visualization of the “friend of a friend” ontology can be found here). Datafication of human signs, be they linguistic, artistic, or part of the historical record, therefore exposes the challenges of data production in particularly evident ways.
