

Most humanists get a bit frightened, if the term „big data” is being mentioned in a conversation; they are often simply not aware of big datasets provided by huge digital libraries like Google Books and Europeana, the USC Shoah Foundation Visual History Archive, or historical census and economic data, to name a few examples. Furthermore, there is a certain oblivion of historical precursors of ‘digital methods’ and the continuities between manual and computer aided methods. Who in the humanities is aware, for example, of the fact that already in 1851 a certain Augustus de Morgan brought forward the idea to identify an author by the average length of his words?
The disconcertment in the humanities with regard to ‘big data’ is certainly understandable, since it points to the premises of the related disciplines and their long-practiced methodologies. Hermeneutics, for example, can be understood as a holistic penetration through individualistic comprehension. It is an iterative, self-reflexive process, which aims at interpretation. Humanists work on the exemplary and are not necessarily interested in generalization and exact quantities.
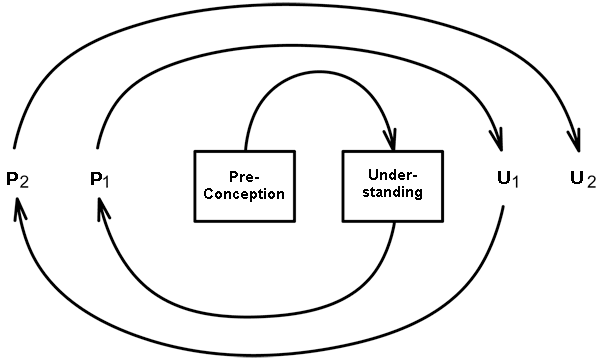
Big Data, by contrast, provide for considerable quantities and point to larger structures, stratification and the characteristics of larger groups rather than the individual. But this seeming opposition does not mean that there are no bridges between humanities’ and big data approaches. Humanists can as well expand their research questions with respect to the ‘longue durée’ or larger groups of people. To provide for an example from text studies: A humanist can develop her comprehension of single authors; her comprehension of the relationship between these single authors and the intellectual contexts they live in; and her comprehension of these intellectual contexts, i.e. the larger environment of individuals, the discursive structures prevailing at the time which is being researched, and the socio-economic conditions determining these structures.
That is not to say that humanities and big data could easily blend into each other. A technique like ‘predictive analysis’, for example, is more or less alien to humanistic research. And there is the critical reservation of the humanities with respect to big data: No computing will ever replace the estimation and interpretation of the humanist.
It is therefore both a reminder and an appeal to humanists to bring back the ‘human’ to big data: The critical perspective of the humanities is able to compensate for the loss of reality which big data inevitably implicates; to situate big data regimes in time and space; to critically appraise the categories of supposedly neutral and transparent datasets and tools, which obscure their relationship to human beings; and to reveal the issues of trust, privacy, dignity, and consent inextricably connected to big data.
The strengths of the humanities – the hermeneutic circle, precise observation of details, complex syntheses, long chains of argumentation, the ability to handle alterity, and the creation of meaning – are capacities which have yet to be exploited in the handling of big data.

One thought on “On the humanities and „Big Data“”