In this article Leo Breiman describes two approaches in statistics: One assumes that the data are generated by a given stochastic data model. The other uses algorithmic models and treats the data mechanism as unknown.
Statisticians in applied research consider data modeling as the template for statistical analysis and focus within their range of multivariate analysis tools on discriminant analysis and logistic regression in classification and multiple linear regression in regression. This approach has the plus that it produces a simple and understandable picture of the relationship between the input variables and response. But the assumption that the data model is an emulation of nature is not necessarily right and can lead to wrong conclusions.
The algorithmic approach uses neural nets and decision trees; predictive accuracy as criterion to judge the quality of the results of analysis. This approach does not apply data models to explain the relationship between input variable x and output variable y, but treats this relationship as a black box. Hence the focus is on finding an algorithm f(x) such that for future x in a test set, f(x) will be a good predictor of y. While this approach has seen major advances in machine learning, it lacks interpretability of the relationship between prediction and response variables.
This article has been published in 2001, when the word “Big Data” was not yet in everybody’s mouth. But by shaping two different cultures to analyzing data and balancing pros and cons of each approach, it makes the differences of big data analysis in contrast to stochastic data models understandable even to laymen.
Leo Breiman, Statistical Modeling: The Two Cultures. In: Statistical Science, Vol. 16 (2001), No. 3, 199-231. Freely vailable online here.
After mobile devices and touchscreens, personal assistants will be “the next big thing” in the tech industry. Amazon’s Alexa, Microsoft’s Cortana, Google Home, Apple’s HomePod – all these voice-controlled systems come to your home, driven by artificial intelligence, ready for dialogues. Artificial intelligence currently works bests when provided with clear tasks, where clear goals are defined. That can be a goal defined by the user (“Please turn down the music, Alexa!”), but generally the goals of the companies offering personal assistants dominate: They want to sell. And there you find the differences between these personal assistants: Alexa sells the whole range of products marketed by Amazon, Cortana eases access to Microsoft’s soft- and hardware, Google Home has its strengths with smart home devices and the internet of things, and Apple’s HomePod … well, urges you into the hall of mirrors which has been created by Apple’s Genius and other flavour enhancers.
Beyond well-defined tasks, artificial intelligence is bad at chatting and assisting. If you are looking for a partner, for someone to talk to, the predefined goals are missing. AI lacks the world knowledge needed for such a task, nor is it capable to provide for the appropriateness of answers in a conversation or for the similarity of mindsets which is the basis of friendship.
But this is exactly what is promised by the emotion robot “Pepper”. This robot saves the emotions it collects from its human interaction partners on a shared server, a cloud. All of the existing Pepper robots are connected to this cloud. This way the robots, which are already autonomous, collectively “learn” how to improve their emotional reactions. Their developers also work with these data.
If you think through the idea of “Pepper”, you have to ask yourself to which end this robot should serve – as a replacement of a partner for human beings, caring for their emotional well-being? In which way is this conceived of? How does a robot know how to contribute to human well-being? Imagine of a human couple, where he is a choleric, and her role is to constantly quieten him down (contrapuntal approach). Or another couple which is constantly quarrelling, he shouts at her, and she yells back; this couple judges this to be the normal state and their quarrelling as an expression of well-being (homeopathic approach). Can a robot decide which ‘approach’ is the best? Simply imagine what would happen in a scenario where you have a person – we call him ‘Donald’ – who buys a new emotion robot – whom we call ‘Kim’. Certainly this is not the kind of world we’re looking for, isn’t it?
With personal assistants, it seems to be a choice between the devil and the deep blue sea: Either you are being reduced to a consumer; or you’ll be confronted with some strange product without openly defined goals, with which you can’t exchange at eye level. So the best choices we have is to either abstain from using these AIs; or to participate in civil society dialogues with tech companies on policy debates about the use of AI.
As researchers of the social, we are often pre-occupied with ways in which knowledge is governed and controlled in order not to upset hegemonic narratives, but we are reminded every day that anyone can produce knowledge. Inspirational stories of unorthodox investigators and inventors making surprising discoveries abound. They solve problems with one weird trick. Trainers hate them. When particular methods of knowledge creation catch the popular imagination, they stir us to wonder at the achievements of human enquiry and the possibilities of collective endeavour. Citizen-scientists’ efforts to map the universe offer a welcome break in headlines reminding us of humanity’s penchant for self-destruction, as well as evoking a sense of awe at the scale of achievement possible when a critical mass of committed, anonymous volunteers chip away at raw material to carve out a work of staggering complexity.
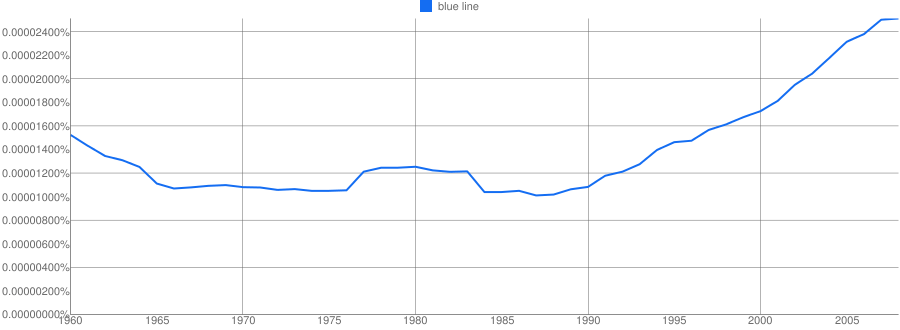
The allure of stumbling upon a breakthrough that puts experts’ ‘persistent plodding’ (Wang 1963: 93) to shame fosters fervour for emergent tools like the Ngram Viewer, which led Rosenberg to comment that ‘briefly, it seemed that everyone was ngramming’ (2013: 24). When the means of knowledge production are seemingly in the hands of the people, we are tantalised by a fantasy of taking power from those elites who would otherwise govern it, but of course, we are still using the master’s tools. Whether the master is Google – whose Google Books capture about a fifth of the world’s library, and which made a third of those available through the Ngram Viewer – or any other mediator, the citizen-researcher should be wary of the black box, and the weird tricks they conjure from it.
An Ngram
Seasoned researchers may consider themselves hyper-aware of dominant discourses, and no-one takes up a position thinking they’ve been duped into the values they hold dear. When virtue-signalling brands like Innocent and Lush cute-bomb us with faux-naïve descriptions of their purity and messages from their workforce of dedicated artisans, we all like to think we can see through their studied informality to the processes of mass production. Borgman (2015) writes of the ‘magic hands’ of specialised, local, expert knowledge production and that which can be replicated on an industrial scale. Both have their place and there is an enduring belief that there are some areas for which the small-scale artisan’s skills are irreplaceable, but which end of the spectrum is most likely to throw up surprises that challenge accepted thinking?
We like to think there is a difference between human, humane craft and computerised, robotic task fulfilment, and we all had a good laugh when that police robot fell down those stairs to its watery grave because we like to think the human perspective adds a special je ne sais quoi beyond the competence of machines. So even where hundreds of artisanal citizen-data-harvesters come together to produce a multi-perspective synth of Venice’s Piazza San Marco, the inherent complexity of this technological mediation cannot be equated with the singular, human perspective of Canaletto’s artistic rendering.
We are wary of the mediation of technology. We therefore allow technology to serve us, to answer the questions we had conceived it to answer, but we are still uncomfortable with the implications of allowing it to suggest new questions. Uricchio points out that journalistic pronouncements on the potentially dystopic applications of new technology have become a trope. The Algorithm, referred to as a synecdoche for various black boxes, evokes a vision of a merciless god to be feared and worshipped:
The recent explosion of headlines where the term ‘algorithm’ figures prominently and often apocalyptically suggests that we are re-enacting a familiar ritual in which ‘new’ technologies appear in the regalia of disruption. But the emerging algorithmic regime is more than ‘just another’ temporarily unruly new technology. (Uricchio, 2017: 125)
The Data Deluge
So could the right mix of data and algorithms disrupt our looping endlessly on the same track, elevating us above the Matthew Effect to a higher plain of enlightenment? Is this our era-defining opportunity to emerge from the data deluge with a trove of knowledge, the munificence of knowing exactly where to look? Well possibly, but only if that possibility is already within us, or at least, within those of us creating the algorithms. As Bowker reminds us:
Our knowledge professionals see selfish genes because that’s the way that we look at ourselves as social beings—if the same amount of energy had been applied to the universality of parasitism/symbiosis as has been applied to rampant individualistic analysis, we would see the natural and social worlds very differently. However, scientists tend to get inspired by and garner funding for concepts that sit “naturally” with our views of ourselves. The social, then, is other than the natural and should/must be modeled on it; and yet the natural is always already social. (Bowker 2013: 168)
Uricchio (2017: 126) is also sceptical, noting that the ‘dyad of big data and algorithms can enable new cultural and social forms, or they can be made to reinforce the most egregious aspects of our present social order’; yet he is more hopeful that the computational turn has the power to surprise us:
The new era has yet to be defined, and it is impossible to know how future historians will inscribe our trajectory. Of course, the ‘newness’ of this regime comes with the danger that it will be retrofitted to sustain the excesses and contradictions of the fast-aging modern, to empower particular individual points of view, to control and stabilize a master narrative. But it also offers an opportunity for critical thinking and an imaginative embrace of the era’s new affordances. And for these opportunities to be realized, we need to develop critical perspectives, to develop analytical categories relevant to these developments and our place in them. (Uricchio, 2017: 136)
Our critical capacity is therefore our indemnity against the seduction of surprising discoveries, helping us to judge and accept that which is novel and valid. By interrogating the implications of new areas of inquiry from the start, we can avoid the danger of our creations escaping our control and serving undesirable ends. If we use the computational turn as an opportunity to strengthen critical thought, we might just find our way through the new complexities of knowledge without any nasty surprises.
Borgman, C. L. (2015). Big data, little data, no data: Scholarship in the networked world. Cambridge, Massachusetts: MIT press.
Bowker, G. (2013). Data Flakes: An Afterword to “Raw Data” Is an Oxymoron. in Gitelman, L. (2013). “Raw Data” Is an Oxymoron. Cambridge, Massachusetts: MIT press.
Rosenberg, D. (2013). Data Before the Fact. in Gitelman, L. (2013). “Raw Data” Is an Oxymoron. Cambridge, Massachusetts: MIT press.
Uricchio, W. (2017). Data, Culture and the Ambivalence of Algorithms. in Schäfer, M.T. and van Es, K. (2017). The Datafied Society: studying culture through data. Amsterdam: Amsterdam University Press.
Wang, H. (1963). Toward Mechanical Mathematics. in The modelling of Mind, ed. K.M. Sayre & F.J. Crosson. South Bend, IN: Notre Dame University Press.
Annual leaves and holidays seem to support regressive impulses: Nearly unvoluntarily one stops in front of a souvenir shop to inspect rotating displays with postcards on it. They definitely have a charm of their own – small-sized cardboards with the aura of authenticity, indicating in a special way that “I was here”, as if there weren’t enough selfies and WhatsApp-posts to support that claim. Quickly written and quickly sent, these relicts of a faraway time in which messages were handwritten, postcards seem to provide for a proof that someone has really been far away and happily came back, enriched by experiences of alterity.
This aura of the analogue, which provides a short insight into the inner life of a person distantly on his route, is being exploited by an art project since many years. Postsecret.com provides post office boxes in many countries of the world, where people can send in their postcard, anonymously revealing a personal secret. A simple and ingenious idea: One can utter something which can not be told by word of mouth; nor could it be written down, because one would need an addressee who would draw his conclusions. But Postsecret.com makes this secret public, and maybe the cathartic effect (and affect) to finally got rid of something which was a heavy burden can be enjoyed in anonymity.
Can we conceive of a digital counterpart of this analogue art project? Only if there are still users there who believe in anonymity in the net. But it is true that literally every activity in the net leaves traces – and why should I reveal secrets in the net and thus become in one way or another susceptible to blackmail?
Praise for the good old hand-written postcard of confidence: Every mailing is an original, every self-made postcard is unique.
Could a complete worldwide list of all the names of streets, squares, parks, bridges, etc. be considered as big data? Would the analysis of frequencies and the spatial distribution of these names tell us anything about ourselves?
Such a comparative analysis would miss important information, especially the historical changes of names and the cultural significance embedded therein.
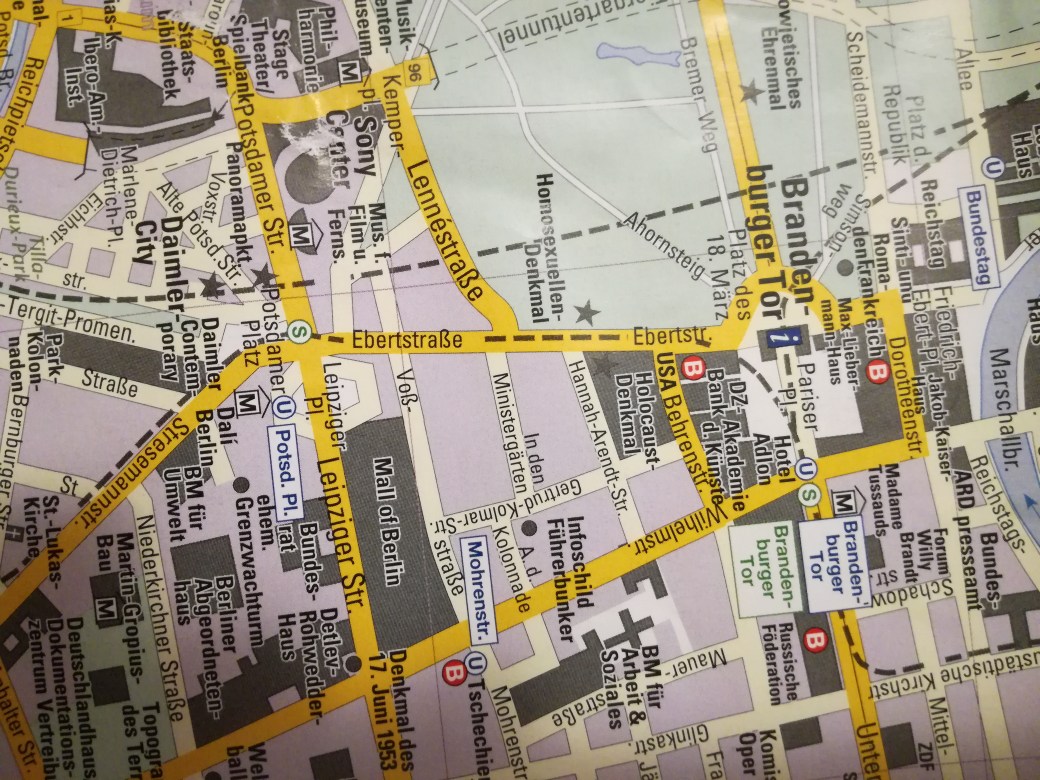
The Ebertstraße in Berlin had changed its name several times: in the 19th century it became the Königgrätzer Straße after the Prussian victory over Austria at the Battle of Königgrätz, during the First World War it was renamed in Budapester Straße, in 1925 it got the name Friedrich-Ebert-Straße in memorial of the first President of the Weimar Republic. Shortly after the Nazi took over in Germany the street was renamed in Hermann-Göring-Straße after the newly elected President of the Reichstag. Only in 1947 the street was finally renamed back to Ebertstraße.
The close-by Mohrenstraße on the other hand bears its name since the beginning of the 18th century. One of the myths on the origin of the street name stems from African musicians who played in the Prussian army. Debates on changing the street name remain and University departments which are located in that street chose to use Møhrenstraße in the meantime.
So, if even if street names are not as rich cultural data as the painting of Mona Lisa, they convey meaning that has been formed, changed and negotiated over a long period of time.
But in order to reveal the history of street names one should not restrict oneself to the evidence on, about and of street names but dig into the events, processes, narratives and politics related to the context of origin. The HyperCities project has set up a digital map that allows “thick mapping”.
Certainly such a research will lead to the creation of narratives itself – that might be biased overall – but in the face of historical events is there any objective account possible at all?
Predicting the future has always been a concern for positivist scientists. The theories and models they constructed claimed not only to represent general laws but also to forecast the prospective outcomes of long-term processes. Take for example the predecessor of sociology, Auguste Comte, who tried to explain the past development of humanity and predict its future course. Even Karl Marx, who criticized the limited conception of cause underlying positivist natural laws, developed a theory of history for Western Europe that saw socialism and communism as the final stages after epochs of slavery, feudalism and capitalism. In addition to description and explanation the predictive power was and is crucial for the scientific worth of theories.
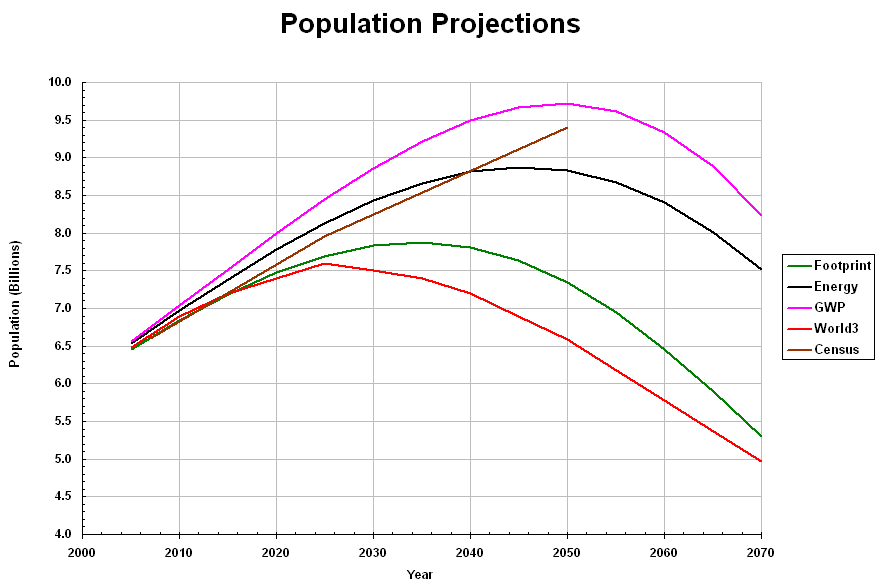
Predictions about the future often rely on a combination of historical data and interpretations informed by current theories. A review of 65 estimates of how many people the earth can support for instance show how widely these differ: “The estimates have varied from <1 billion to >1000 billion”. The review also shows the different methods used for estimating human carrying capacity. The first estimation in the 17th century which stated 13.4 billion people extrapolated the number of inhabitants in Holland to the earth’s inhabited land area. Estimations from the 20th century are based on food and water supply and individual requirements thereof.
Recent estimations rely on computer models that integrate data and theories related to growth. Different scenarios are developed that estimate the maximum global population at about 9 billion people in the 21st century and then either to collapse or to adapt smoothly to the carrying capacity of the earth.
Estimations of this kind should be viewed with caution, because the information provided is incomplete. We might have some idea about the desirable level of material well-being and the physical environments we want to live in, but we cannot foresee the technologies, economic arrangements or the political institutions in place in fifty or eighty years. These mechanisms do not operate independently but interact and produce feedback loops. The awareness of dangers and risks alone won’t necessarily change predominant policies. Human behavior and the underlying fashions, tastes and values (on family size, equality, stability and sustainability) are too complex to be predicted accurately.
Let’s try then a more modest example! What about predicting the potential outbreak of a disease? Google Flu Trends was a program that aimed for better influenza forecasting than the U.S. Centers for Disease Control and Prevention. From 2008 onwards internet searches for information on symptoms, stages and remedies were analyzed in order to predict where and how severely the flu would strike next. The program failed. Big data inconsistencies and human errors in interpreting the data are held responsible for not predicting the flu outbreak in the United States in 2013, the worst outbreak of influenza in ten years. Another recent example is the Ebola epidemic in West Africa in 2014. The U.S. Centers for Disease Control and Prevention published a worst-case prediction with 1.4 million people infected. The World Health Organization predicted a 90% death rate from the disease, in retrospect the rate is about 70%. The data and the model based on initial outbreak conditions turned out inadequate for projections. Disease conditions and human behavior changed too quickly for humans and algorithms to keep up.
OK, then how about sales forecasting, a comparatively easy task? Mass-scale historical data has served eBay and other companies to measure the benefit of search advertising. In a simple predictive model clicks were counted to predict sales: “Although a click on an eBay ad was a strong predictor of a sale – consumers typically purchased right after clicking – the experiment revealed that a click did not have nearly as large a causal effect, because the consumers who clicked were likely to purchase, anyway”.
This shows us that data alone are not enough for prediction, one needs to know about causal effects and context information. Additionally, purely data-driven approaches tend to produce models and algorithms that are overfit to the idiosyncrasies of particular circumstances. What theories and models can deliver is not knowledge of the future but at best the ability to rule out a range of futures as unrealistic.
Everything new is blank. New things display their integrity and an undestroyed, immaculate surface. Design objects are icons of youth and timelessness. They demand attention in a special way, because their newness is always at risk. Traces like scratches rob them of their stainlessness and indicate a loss of aura. The ageing of these objects triggers a certain horror in their owners, because it shows the passing of newness and a loss of control. Consumer electronics is a particularly instructive example here, and this is in spite of a miraculous ability of electronic content – the ability NOT to age.
But ageing is precious. Aged objects, which can be found on flea markets, in museums or antique shops are often seen as precious. They represent the past, time, and history, and we appreciate the peculiarities of their surface, which has grown over decades. We are not disturbed by dust, grease, grime, wax, scratches, or cracks – on the contrary, the patina of objects represents their depth and their ability to exhibit their own ageing process. The attention of the observer focuses on the materiality of the object, the patina of the surface and the deformations gained in time mark their singularity and individuality. To be precise: The fascination of the observer focuses more on the signs of ageing, rather than on the object itself.
Schoolbag from a flu market
In the digital world, we don’t find comparable qualities. Ageing would mean that data have become corrupt, unreadable, unusable and therefore worthless. For objects digitized by cultural heritage institutions, this is a catastrophe; it means loss. With consumer electronics, it’s similar: A smartphone is devalued by scratches. No gain in singularity is noted. With software, it is even worse. Software ageing is a phenomenon, where the software itself keeps its integrity and functionality, but if the environment, in which this software works, or the operating system changes, the software will create problems and mistakes, and sooner or later it will become dysfunctional. Ageing here means an incapability to adapt to the digital environment, and surprisingly this happens without wear or deterioration, since it is not data corruption which causes this ageing. In this respect, the process of software ageing can be compared to the ageing of human beings: They drag behind time or are uncoupled of the social world they live in; they lose connectivity, the ability of actualisation, and the skill to exchange with their environment.
With analogue objects, this is not the case. They provoke sensual pleasures without reminding the observer of the negative aspects of human ageing. Even if they have become dysfunctional and useless, they keep the dignity and aura of time, inscribed into their body and surface. They keep their observers at a beneficial distance, which opens up space for imagination and empathy. The observer is free to visualise to himself the history of these objects and their capability to endure long time distances without vanishing – certainly a faculty which human beings do not dispose of. What remains are the characteristics of dignified ageing. While the nasty implications of ageing are buried in oblivion, analogue objects evoke a beauty of ageing.
So far we have learnt about the most popular three criteria of big data: volume, velocity and variety. Jennifer Edmond suggested adding voluptuousness as fourth criteria of (cultural) big data.
I will now discuss two more “V” of big data that are often mentioned: veracity and value. Veracity refers to source reliability, information credibility and content validity. In the book chapter “Data before the Fact” Daniel Rosenberg (2013: 37) argued: “Data has no truth. Even today, when we speak of data, we make no assumptions at all about veracity”. Many other scholars agree with this, see: Data before the (alternative) facts.
What has been questioned for “ordinary” data seems to hold true for big data. Is this because big data is thought to comprise statistical population data, not just data of a sample? Does the assumed totality of data reveal the previously hidden truth? Instead of relying on a model or on probability distributions, we could now assess and analyse data of the entire population. But apart from the implications for statistical analysis (higher chances of getting false-positives, need for tight statistical significance levels, etc.) there are even more fundamental problems with the veracity of big data.
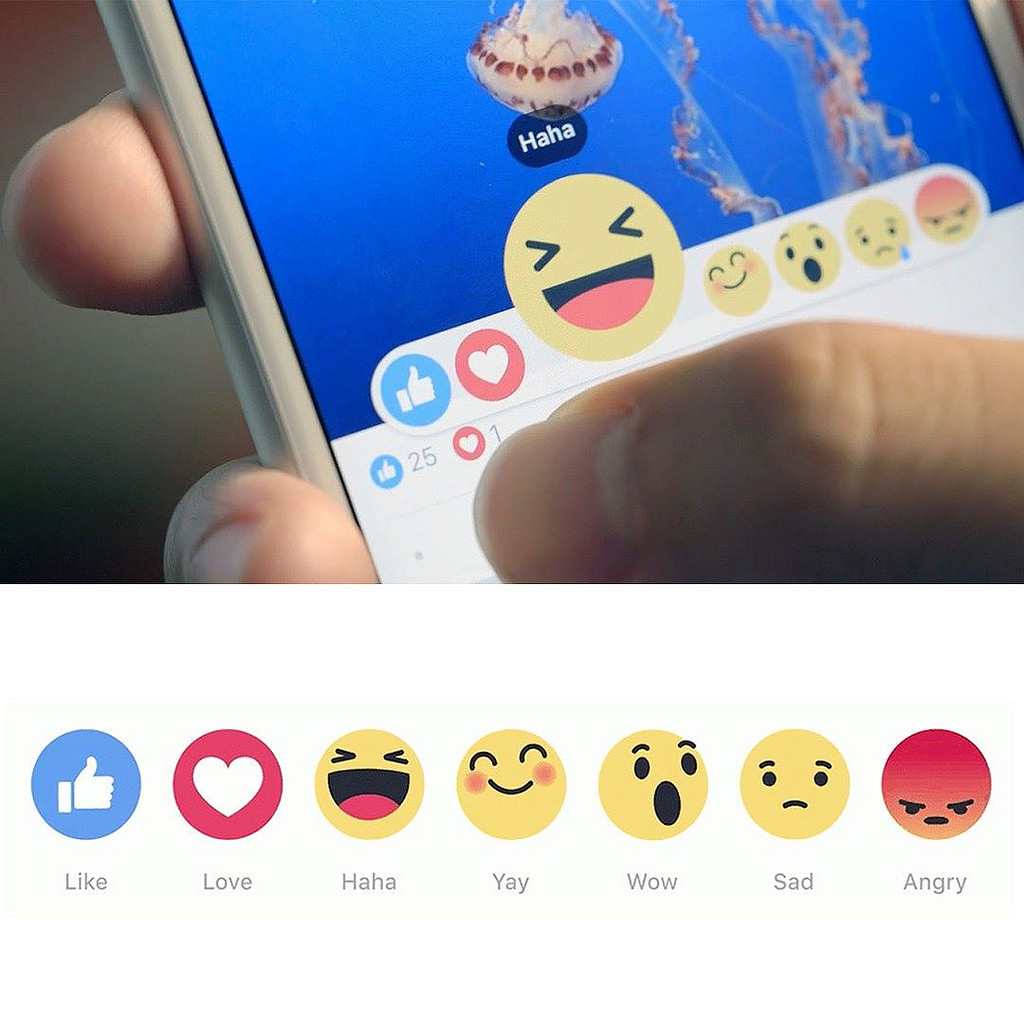
Take the case of Facebook emoji reactions. They have been introduced in February 2016 to give users the opportunity to react to a post by tapping either Like, Love, Haha, Wow, Sad or Angry. Not only is the choice of affective states very limited and the expression of mixed emotions impossible but the ambiguity in using these expressions themselves is problematic. Although Facebook reminds its users: “It’s important to use Reactions in the way it was originally intended for Facebook — as a quick and easy way to express how you feel. […] Don’t associate a Reaction with something that doesn’t match its emotional intent (ex: ‘choose angry if you like the cute kitten’)”, we do know that human perceptions as well as motives and ways of acting and reacting are manifold. Emojis can be used to add emotional or situational meaning, to adjust tone, to make a message more engaging to the recipient, to manage conversations or to maintain relationships. Social and linguistic function of emojis are complex and varied. Big Data in the case of Facebook emoji reactions then seems to be as pre-factual and rhetorical as “ordinary” data.
Value now refers to social and economic value that big data might create. When reading documents like the European Big Data Value Strategic Research Innovation Agenda one gets the impression of economic value dominating. The focus is directed to “fuelling innovation, driving new business models, and supporting increased productivity and competitiveness”, “increase business opportunities through business intelligence and analytics” as well as to the “creation of value from Big Data for increased productivity, optimised production, more efficient logistics”. Big Data value is not speculative anymore: “Data-driven paradigms will emerge where information is proactively extracted through data discovery techniques and systems are anticipating the user’s information needs. […] Content and information will find organisations and consumers, rather than vice versa, with a seamless content experience”.
Facebook emoji reactions are just an example of this trend. Analysing users’ reactions allows not only for “better filter the News Feed to show more things that Wow us” but probably also to change consumer behavior and sell individualized products and services.
As always in a field where different conceptions are present, there exist differing understandings of what ‘tidy’ or ‘clean’ data on the one hand, and ‘messy’ data on the other might be.
On a very basic level, and coming from the notion of data arranged in tables, Hadley Wickham has defined ‘tidy data’ as those where each variable is a column, each observation is a row, and each type of observational unit is a table. Data not following these rules are understood as messy. Moreover, data cleaning is a routine procedure in statistics and private companies applied to the data gathered: judging the number and importance of missing values, correcting obvious inconsistencies and errors, normalization, deduplication etc. Common examples are the use of non-existing or incorrect postal codes, a number which wrongly indicates an age (in comparison to birth date), the conversion of names from “Mr. Smith” to “John Smith”, etc.
In the sciences, the understanding of ‘messy’ data largely depends on what is understood as ‘signal’ and what is seen as ‘noise’. Instruments collect a lot of data, and only the initiated are able to distinguish between them. Cleaning data and thus peeling out the relevant information in order to receive scientific facts is also a standard procedure here. In settings where the data structure is human-made rather than technically determined, ‘messy’ data remind scientists to reassess whether the relationship between the (research) question and the object of research is appropriate; whether the classifications used to form variables are properly conceived of or whether they inappropriately limit the phenomenon under question; and what kind of data can be found in that garbage category of the ‘other’.
In the humanities, this is not as easily the case as it is with the sciences. Two recent publications provide for examples. Julia Silge’s and David Robinson’s book “Text Mining with R” (2017) bears the subtitle “A tidy approach”. Very much like Wickham, they define ‘tidy text’ as “a table with one-token-per-row”. Brandon Walsh and Sarah Horowitz present in their “Introduction to Text Analysis” (2016) a more differentiated approach to an understanding of what ‘cleaning’ of ‘messy’ data might look like. They introduce their readers to the usual problems of cleaning dirty OCR; the standardization and disambiguation of names (their well-chosen example is Arthur Conan Doyle, who was born as Arthur Doyle, but used one of his given names as addendum to his last name); and the challenges posed by metadata standards. All that seems easy stuff at first glance, but think of Gothic types (there exist more than 3.000 of them), pseudonyms or heteronyms, or camouflage printings published during the inquisition or under political repression. Now you can imagine how hard it can be to keep your data ‘clean’.
And there is, last but not least, another conception of ‘messiness’ in the humanities. It lies in the specific cultural richness, or polysemy, or voluptuousness of the data (or the sources, the research material) under question: A text, an image, a video, a theater play or any other object of research can be interpreted from a range of viewpoints. Humanists are well aware of the fact that the choice of a theory or a methodological approach – the ‘grid’ which provides order to the chaos of what is being examined – never provides an exhausting interpretation. It is the ‘messiness’ of the data under consideration which provides the foundation of alternative approaches and research results, which is responsible for the resistance to interpretation (and, with Paul de Man, to theory) – and which continuously demands an openness towards seeing things in another way.
Databases as collections of data are not a new phenomenon. Several centuries ago, collections began to emerge all over the world, as for instance the manuscript collections of Timbuktu (in medieval times a centre for Islamic scholars) demonstrate. The number of these manuscripts is estimated at about 300,000 in all the different domains such as Qur’anic exegesis, Arabic language and rhetoric, law and politics, astronomy and medicine, trade reports, etc.
Usually the memory of many people does not go back so far. They might relate today’s databases with the efforts of establishing universalizing classification systems, which began in the nineteenth century.
The transition to digital databases took place only very recently and this explains why many databases are still underway to digitization.
I will present the database eHRAF World Cultures to illustrate this point. This online database originated as “Collection of Ethnography” by the research programme “Human Relations Area Files” that started back in the 1940s at Yale University. The original aim of anthropologist George Peter Murdock was to allow for global comparisons in terms of human behaviour, social life, customs, material culture, and human-ecological environments. To implement this research endeavour it was thought necessary “to have a complete list of the world’s cultures – the Outline of World Cultures, which has about 2,000 described cultures – and include in the HRAF Collection of Ethnography (then available on paper) about ¼ of the world’s cultures. The available literature was much smaller then, so the million or so pages collected could have been about ¼ of the existing literature at that time”.
From the 1960s onwards, the contents of this collection of monographs, journal articles, dissertations, manuscripts, etc. have been converted into microfiche before in 1994 the digitization of the database was launched. The first online version of the database “eHRAF World Cultures” was available in 1997. This digitization process is far from accomplished. Up to now additional 15,000 pages are converted from the microfiche collection and integrated in the online database every year. Currently the database contains data about more than 300 cultures worldwide.
So what does make this database proto-digital then?
First of all it is the research function. When the subject-indexing – at the paragraph level (!) –was done, it was done manually. The standard that provided the guidelines for what and how to index the content of the texts is called the Outline of Cultural Materials and was at that time very elaborate. It assembles more than 700 topic identifiers, clustered into more than 90 subject groups.
The three digit numbers, e.g. 850 for the subject group “Infancy and Childhood” or 855 for the subject “Child Care” ought to facilitate the search for concepts and retrieve data also in other languages than English. And although Boolean searches allow combinations of subject categories and key words, cultures, countries or regions, one has to adapt the logic of this ethnographic classification system in order to carry out purposeful search operations. The organisation of the database was obviously conceptualised in a hierarchical way. If you want to get a particular piece of information, then you look up the superordinate concept and decide which subjects of this group you will need to apply to your research to get the expected results.
Secondly, although the “Outline of Cultural Materials” thesaurus is continually being extended there is no system for providing updates. Only once a year a new list of subject and subject groups is published (online, in PDF and in print).
Thirdly, data that would contribute to better localise cultural groups, such as GIS data (latitude and longitude coordinates) are not available in eHRAF.
At last, users can print or email search results and selected paragraphs or pages from documents, but there is no feature to export data from eHRAF into a (qualitative) data analysis software. The “eHRAF World Cultures” database is also not compatible with OpenURL.
The way from analogue to digital databases is apparently a long and difficult one. The curatorial agency of the database structure and the still discernible influence of the people who assigned the subjects to the database materials should now be a bit clearer.







{kind=link}